惵嶳妛堾戝妛旤揧嫵庼
AI偺尨揰傪扵傞丅儀僀僘摑寁庤朄偲價僢僌僨乕僞丄AI

惵嶳妛堾戝妛偺旤揧懽恖嫵庼
丂價僢僌僨乕僞張棟傗俙俬媄弍偺敪払偑偙偺偲偙傠媫寖偱偁傞丅偙傟偼僴乕僪傗婡夿妛廗側偳偺敪払偺寢壥偩偑丄偙傟傜媄弍偺婎慴傪惉偡傕偺偺堦偮偑摑寁妛揑庤朄偩丅 丂崱夞偼丄價僢僌僨乕僞張棟傗俙俬奐敪偵廳梫側栶妱傪壥偨偟偰偄傞摑寁庤朄丄乽儀僀僘摑寁乿尋媶偵挿擭実傢偭偰偄傞惵嶳妛堾戝妛偺旤揧懽恖嫵庼偵俙俬妛廗偺尨揰偲偟偰偺摑寁妛偲偙傟偐傜偺壽戣偵偮偄偰偍榖捀偄偨丅
乽儀僀僘摑寁庤朄偲偼乿
乗乗傑偢丄愭惗偺偛愱栧偱偁傞儀僀僘摑寁庤朄偵偮偄偰丄懠偺摑寁庤朄偲偺堘偄傪嫵偊偰偔偩偝偄丅
丂俙丗摑寁偼丄乽婰弎摑寁乿偲乽悇寁摑寁乿偑拞怱偱偟偨偑丄嵟嬤偱偼偙傟偵壛偊偰乽儀僀僘摑寁乿偑廳梫偲側傝傑偟偨丅婰弎摑寁偼丄娤應傗挷嵏偱摼傜傟偨僨乕僞傪岠壥揑偵昞尰偡傞庤朄偵娭偡傞傕偺偱偡丅悇寁摑寁偼丄婰弎摑寁偱摼傜傟偨寢壥側偳傪尦偵悢抣傪梊應偟偨傝丄壖愢乮棟榑乯偑丄偳偺掱搙尰幚偺娤應寢壥偲揔崌偡傞偺偐傪専掕偟偨傝偡傞傕偺偱偡丅儀僀僘摑寁傕僨乕僞暘愅偵梡偄傜傟傑偡偑丄妋棪偺夝庍偵戝偒側堘偄偑偁傝丄娤應抣埲奜偺忣曬偺棙梡曽朄偑堎側傝傑偡丅
乽儀僀僘摑寁庤朄偺摿挜乿
丂乗乗嬶懱揑偵偼偳偆偄偆偙偲偱偟傚偆偐丅
丂俙丗儀僀僘摑寁偵傕偄傠偄傠偁傝傑偡偑丄偄偢傟傕夝愅偵乽庡娤妋棪乿乮敾抐妋棪乯偲偄偆奣擮傪嵦梡偟偰偄傑偡丅屆揟摑寁妛偱偼丄枹抦偱傕妋棪偼屌掕丒媞娤揑悢抣偱偡丅儀僀僘摑寁偱偼丄妋棪偼堄巚寛掕幰偺帩偮忣曬傪斀塮偟偰丄曄壔偡傞偙偲偑偁傝傑偡丅
丂乗乗妋棪傪屻偐傜湏堄揑偵曄偊傜傟丄偦傟偑俙俬婡夿妛廗偺婎慴尨棟偵側偭偰偄傞丠
丂俙丗湏堄揑偵妋棪傪曄峏偡傞偲偄偆偺偼丄儀僀僘摑寁偺岆夝偝傟傗偡偄晹暘偱偡丅儀僀僘棳偵尩枾偵峔惉偝傟偨庡娤妋棪偼丄恖娫偼崌棟揑敾抐傪偡傞偲偄偆尨棟乮岞棟懱宯乯偵婎偯偄偨棟榑偱丄晄妋幚惈偵捈柺偟偰傕乽帺暘偺岠梡娭悢傪嵟戝壔偡傞傛偆偵堄巚寛掕傪峴偆乿偲偄偆傕偺偱偡丅摉慠丄恖偵傛偭偰岠梡娭悢偼堎側傝傑偡丅偟偐偟丄岠梡偑嵟戝偵側傞傛偆偵堄巚寛掕傪峴偆偲偄偆寢榑偑摫偐傟傑偡丅偙傟偑丄儀僀僘摑寁偺尨棟偱偡丅偦偟偰丄偙傟偑廳梫偱偡偑丄堄巚寛掕偺崻嫆忣曬偑捛壛揑偵梌偊傜傟傟偽丄偦傟偵傛傝丄庡娤妋棪偼崌棟揑庤弴偱廋惓偝傟傑偡丅偙偺庤弴偑乽儀僀僘偺岞幃乿偲屇偽傟傞宍幃偱偡乮夝愢嶲徠乯丅
丂乗乗婡夿妛廗偺婎慴偵側傞偲偄偆偙偲偱偡偹丅
丂俙丗戝嶨攃偵偄偊偽偦偆偱丄婡夿妛廗偱偼丄儀僀僘偺掕棟傪棙梡偟偰敾抐傪廋惓偟傑偡丅偨偩偟丄尨棟揑側儀僀僘摑寁偵偼偁傑傝娭怱偼側偔丄宱尡揑偵桳岠偩偐傜棙梡偡傞傛偆偱偡丅僴乕僶乕僪帪戙偺巹偺壎巘偨偪偑暦偄偨傜扱偔偲巚偄傑偡偹丅
丂乗乗俙俬偺媄弍偱儀僀僘偺尨棟傪巊梡偟偨戙昞揑側傕偺偵偼壗偑偁傝傑偡偐丠
丂俙丗椺偊偽丄柪榝儊乕儖怳傝暘偗僼傿儖僞偵儀僀僕傾儞僼傿儖僞偲偄偆傕偺偑偁傝傑偡丅
丂僼傿儖僞嶌惉幰偼丄偁傜偐偠傔丄偄偔偮偐偺僉乕儚乕僪偺慻傒崌傢偣偑柪榝儊乕儖偵娷傑傟偰偄偨斾棪傪僨乕僞儀乕僗偲偟偰搊榐偟偰偍偒傑偡丅偁傞儊乕儖傪庴怣偟偨偲偒偺弶婜忬懺偱偼丄堦斒揑側柪榝儊乕儖偺斾棪偑丄偦傟偑柪榝儊乕儖偱偁傞妋棪偱偡丅儊乕儖偵娷傑傟偰偄傞僉乕儚乕僪偵婎偯偄偰丄僼傿儖僞偼偦傟偑柪榝儊乕儖偱偁傞妋棪傪廋惓偟傑偡丅偙偺偲偒偵儀僀僘偺掕棟偑梡偄傜傟傑偡丅暘椶偵儈僗偑偁傝丄曬崘偑偁傟偽丄偦傟偵婎偯偄偰丄僼傿儖僞偺僨乕僞儀乕僗偼偦偺搒搙廋惓丄夵慞偝傟傑偡丅
乽擔杮偼價僢僌僨乕僞傗俙俬偱抶傟偰偄傞偐乿
乗乗俙俬奐敪傗棙梡丒妶梡偵偮偄偰擔杮偼暷崙傗拞崙偲斾傋抶傟偰偄傞偲偄偄傑偡偑丄僨乕僞偺検偑彮側偔丄晄棙偩側偳偲摑寁揑側柺偑巜揈偝傟偰偄傑偡丅
丂俙丗媄弍柺偱抶傟偰偄傞偲偼姶偠傑偣傫偟丄價僢僌僨乕僞偲偟偰巊梡偱偒傞傕偺偼偄偔傜偱傕偁傝傑偡丅偨偩丄暷崙偵偼丄僌乕僌儖側偳偑偁傞偺偵懳偟價僢僌僨乕僞傪帠嬈偲偡傞戝婇嬈偑彮側偐偭偨偙偲偲丄摑寁揑暘愅擻椡傪廗摼偱偒傞戝妛側偳偑彮側偄偲偄偆偙偲偼偄偊傑偡丅
乽俙俬偺敪揥偵偼摑寁揑暘愅擻椡岦忋偑晄壜寚乿
乗乗変偑崙偱俙俬傪敪揥偝偣偰偄偔偨傔偵偼僌乕僌儖偺傛偆側婇嬈偑昁梫偲偄偆偙偲偱偡偐丠
丂俙丗暷崙偼僆僶儅戝摑椞偑侾俀擭偵弌偟偨乽價僢僌僨乕僞尋媶奐敪僀僯僔傾僥傿僽乿偱價僢僌僨乕僞娭楢媄弍傊偺尋媶奐敪搳帒偑壛懍偟丄俙俬偺奐敪傕恑傒傑偟偨丅擔杮偱偼丄價僢僌僨乕僞偺妶梡丄摑寁揑暘愅擻椡岦忋傊偺巟墖偺昁梫惈偼丄偦傟傑偱偁傑傝擣幆偝傟偰偄傑偣傫偱偟偨丅嵟嬤丄擔杮偱傕惌晎偵傛傞巟墖偑巒傑偭偰偄傑偡丅恖嵽堢惉偵娭偟偰偼丄巹帺恎傕崙嵺揑側悈弨偺摑寁嫵堢偺奼戝偺偨傔丄乽摑寁嫵堢戝妛娫楢実僱僢僩儚乕僋乮俰俬俶俽俤乯乿側偳偱巟墖妶摦傪偟偰偄傑偡丅
丂乗乗價僢僌僨乕僞妶梡偲偟偰偺俙俬偺摑寁妛揑壽戣偼偁傝傑偡偐丅
丂俙丗悽奅揑偵乽價僢僌僨乕僞偺暘愅乿偲偄偆棳傟偑偁傝丄偦偺堄枴偱摑寁揑庤朄偺尋媶丒奐敪偼廳梫壽戣偱偡丅揱摑揑側摑寁妛偩偗偱偼晄廫暘偲偄偆斸敾傕偁傝傑偡偑丄俀侽擭埲忋慜偐傜丄怴偟偄摑寁妛偼廫暘偵敪払偟偰偄傑偡丅栤戣偼丄戝妛摍偱怴偟偄摑寁揑庤朄傪嫵偊傜傟傞恖嵽偑彮側偐偭偨偙偲偱偡丅偝傜偵怴偟偄摑寁揑庤朄偺奐敪偲幚梡壔偑壽戣偱偡偑丄摨帪偵丄俙俬側偳偱價僢僌僨乕僞傪妶梡偡傞堦斒儐乕僓乕偼丄梌偊傜傟偨僨乕僞偵懳偟偰丄揔愗側儌僨儖傪慖戰偱偒傞掱搙偺摑寁揑僨乕僞夝愅擻椡偺廋摼偑媮傔傜傟傑偡丅偙偺傛偆側恖嵽傪偄偐偵堢惉偡傞偐偑丄崱屻偺價僢僌僨乕僞傗俙俬妶梡偱廳梫偩偲巚偄傑偡丅
丂乗乗俙俬偺敪払偱偄傠偄傠栤戣傕敪惗偟偰棃偦偆偱偡偑丅椺偊偽彨棃丄俙俬偑恖娫偺懡偔偺怑嬈傪扗偆偲偄傢傟傑偡偑丅
丂俙丗俙俬偑怺憌妛廗偱帺傜妛傇偵偟偰傕丄摉柺丄栤戣夝寛偺偨傔偺僨乕僞廂廤丄揔愗側儌僨儖偺愝掕傗庤朄偺奐敪偼暘愅幰偑峴偄傑偡丅傑偨丄俙俬偼斈梡揑側栤戣偵懳偟偰偼夞摎傪弌偣偰傕丄偦偺夞摎傪惓摉壔偡傞棟榑偺峔抸偼丄傑偩偱偒側偄傛偆偱偡丅偟偽傜偔偼丄恖娫偵廳梫側懚嵼堄媊偑偁傞偲巚偄傑偡丅
丂乗乗偁傝偑偲偆偛偞偄傑偟偨丅
丂亙庢嵽嫤椡丗惵嶳妛堾戝妛宱塩妛晹丂俰俬俶俽俤亜
夝愢丗儀僀僘摑寁庤朄偵傛傞堄巚寛掕椺乮儌儞僥傿儂乕儖栤戣乯
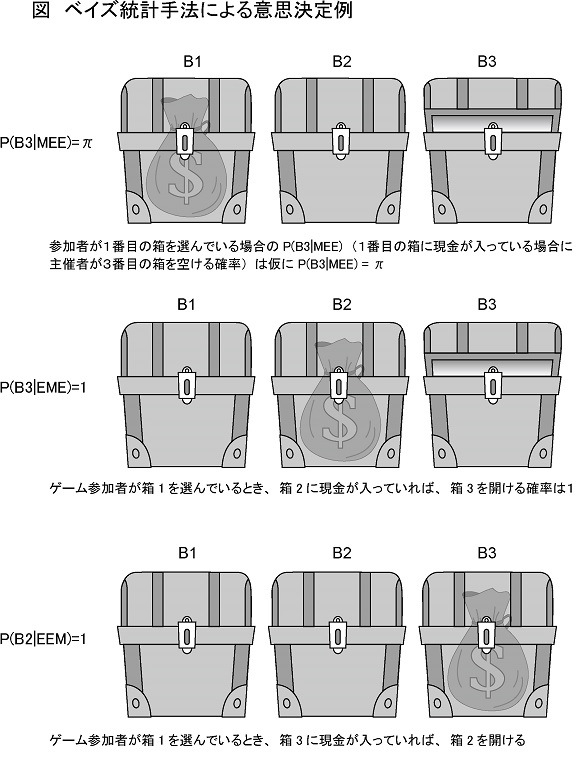
丂偁傞僎乕儉偱丄俁偮偺敔乮俛侾乣俛俁乯偑偁傝丄偦偺偆偪堦偮偵偼丄尰嬥乮俵乯偑擖偭偰偄傞丅偙偺僎乕儉偺嶲壛幰偼偦偺尰嬥偑擖偭偨敔傪侾夞偱奐偗傜傟傟偽丄偦偺拞偺尰嬥偑傕傜偊傞偲偡傞丅嶲壛幰偼丄敔傪奐偗傞慜偵偳偺敔傪奐偗傞偐偁傜偐偠傔寛傔傞乮偙偺椺偱偼丄敔侾丄俛侾傪慖傫偩傕偺偲偡傞乯丅
丂偙偺僎乕儉偺庡嵜幰偼丄偳偺敔偵尰嬥偑擖偭偰偄傞偐抦偭偰偄傞丅傕偪傠傫丄庡嵜幰偼偳偺敔偵擖偭偰偄傞偐傪嶲壛幰偵嫵偊傞偙偲偼側偄偟丄敔傪奐偗偢偵偳偺敔偵尰嬥偑擖偭偰偄傞偐抦傞偡傋偼側偄傕偺偲偡傞丅
丂傑偢丄敔偵擖偭偰偄傞傕偺傪弴斣偵婰弎偟偰偄偔丅椺偊偽丄俵俤俤偼丄侾斣栚偺敔偵尰嬥乮俵倧値倕倷乯偑丄俀丄俁斣栚偑嬻乮俤倣倫倲倷乯偱偁傞偙偲傪昞偡傕偺偡傞丅
丂偙偺偲偒丄嶲壛幰偑峫偊傞尰嬥偑奺敔偵擖偭偰偄傞帠慜妋棪偼丄
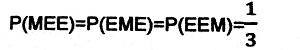
丂庡嵜幰偼丄昁偢嬻偺敔傪奐偗傞偺偱丄俹乮俛俁乥俤俵俤乯亖侾丄俹乮俛俁乥俤俤俵乯亖侽偵側傞丅晄妋掕側偺偼丄嶲壛幰偑侾斣栚偺敔傪慖傫偱偄傞応崌偺俹乮俛俁乥俵俤俤乯乮侾斣栚偺敔偵尰嬥偑擖偭偰偄傞応崌偵庡嵜幰偑俁斣栚偺敔傪奐偗傞妋棪乯偱偁傞偑丄偙傟偼壖偵俹乮俛俁乥俵俤俤乯亖兾偲偟偰偍偔乮恾嶲徠乯丅
丂偙偺偲偒丄俁斣栚偺敔傪奐偄偨屻丄敔傪曄峏偟偰尰嬥偑摉偨傞帠屻妋棪偼丄
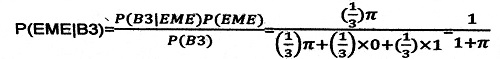
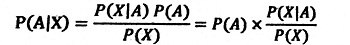
丂丂丂侾
丂兾亖乗丄丂兾亖侾丄丂兾亖侽
丂丂丂俀
丂偙偺嶰偮偺応崌傪岞幃偵摉偰偼傔傞偲丄偦傟偧傟偺帠屻妋棪偼丄
丂俀丂侾
丂乗丄乗丄侾
丂俁丂俀丂丂丂 偲側傝丄帠慜偺妋棪偼丄儀僀僘偺掕棟偵傛傝曄峏偝傟傞丅
旤揧懽恖乮傛偟偧偊丂傗偡偲乯嫵庼乮俹倛丏俢丂摑寁妛乯
棯楌丗侾俋係俇擭惗傑傟
搶嫗戝妛宱嵪妛晹丂侾俋俇俋擭懖嬈
搶嫗戝妛戝妛堾宱嵪妛尋媶壢攷巑壽掱丂侾俋俈俆擭廋椆
僴乕僶乕僪戝妛戝妛堾乮摑寁妛愱峌乯丂侾俋俈俉擭廋椆丄俹倛丏俢丂乮摑寁妛乯
愱栧丒尋媶暘栰丗
儀僀僘摑寁丄摑寁壢妛丄宱嵪摑寁妛
強懏妛夛丒抍懱丗
擔杮摑寁妛夛丄俬俽俬乮崙嵺摑寁嫤夛乯丄懠
庡側栶怑丗擔杮摑寁妛夛棟帠挿丄撪妕晎宱嵪幮夛憤崌尋媶強媞堳庡擟尋媶姱丄憤柋徣摑寁尋廋強媞堳嫵庼丄摑寁怰媍夛夛挿丄摑寁埾堳夛埾堳丄擔杮摑寁妛夛夛挿側偳傪楌擟
尰嵼丗擔杮妛弍夛媍楢実夛堳丄惵嶳妛堾戝妛宱塩妛晹彽阗嫵庼